Nicolás Pavón
ÁRBOLES DE DECISIÓN PARA CLASIFICACIÓN DE IRIS SETOSA
Introducción
En este caso de estudio, vamos a crear árboles de decisión para la clasificación de iris-setosa. Primero, crearemos un árbol de decisión utilizando RapidMiner, y luego, lo haremos con Python y scikit-learn. Finalmente, comparamos los resultados obtenidos.
Modelo en RapidMiner
Definiendo los Operadores Necesarios
Estaremos trabajando con el reconocido dataset de Iris setosa. Convenientemente, RapidMiner ya viene con el dataset pronto para ser usado, así que importar dicho dataset será tan sencillo como agregar un operador Retrieve que se encargue de importarlo de la carpeta Samples/Data.
Luego de importar el dataset, vamos a necesitar crear el modelo, para ello, vamos a usar el operador Decision Tree que nos ofrece RapidMiner. Además, usaremos los operadores Apply Model y Performance (Classification) (ya que sabemos que es un problema de clasificación).
Como último detalle, claramente nos interesa que nuestro modelo sea validado apropiadamente y las métricas obtenidas no nos engañen, así que incluiremos estos últimos tres operadores apropiadamente en un operador de Cross Validation.
Proceso Creado
Luego de agregar y conectar los operadores comentados anteriormente, el proceso de RapidMiner se ve de la siguiente manera.
Proceso principal
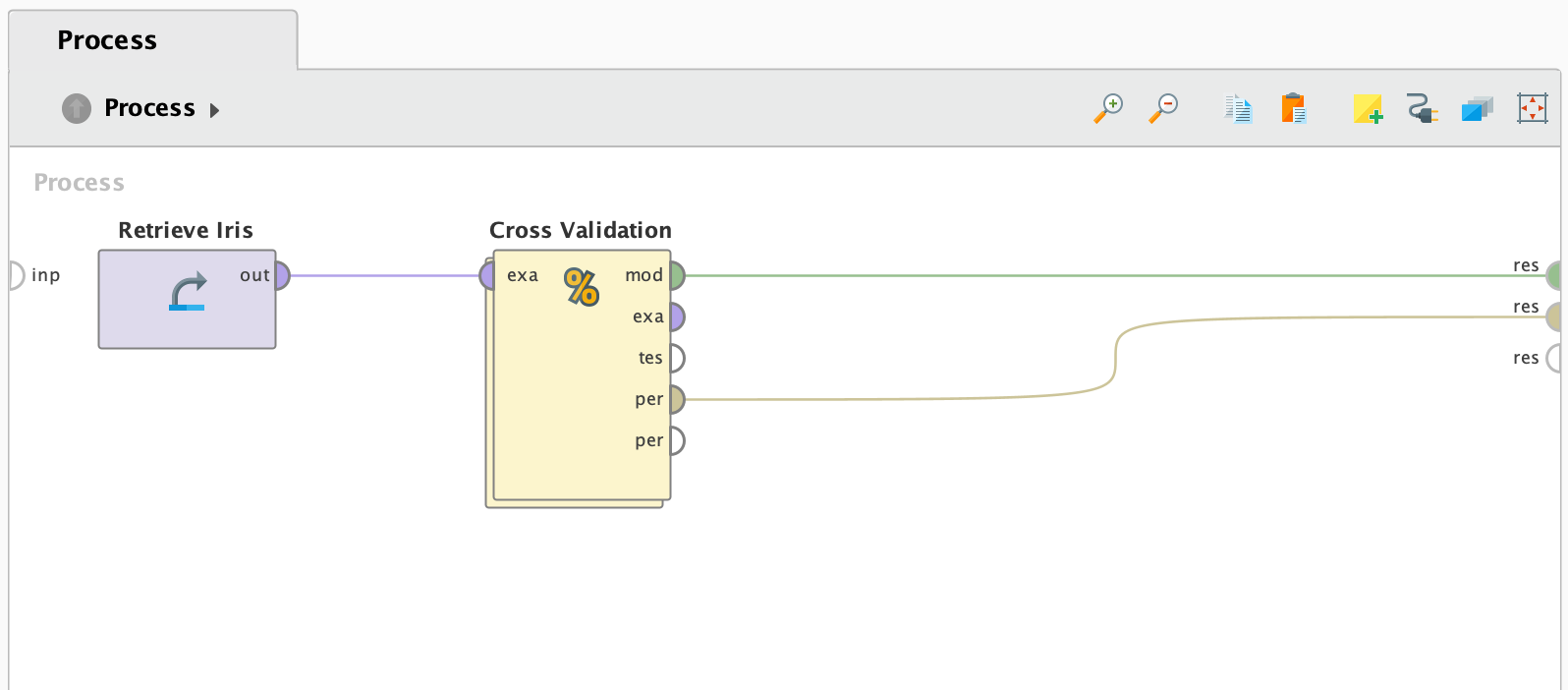
Cross Validation
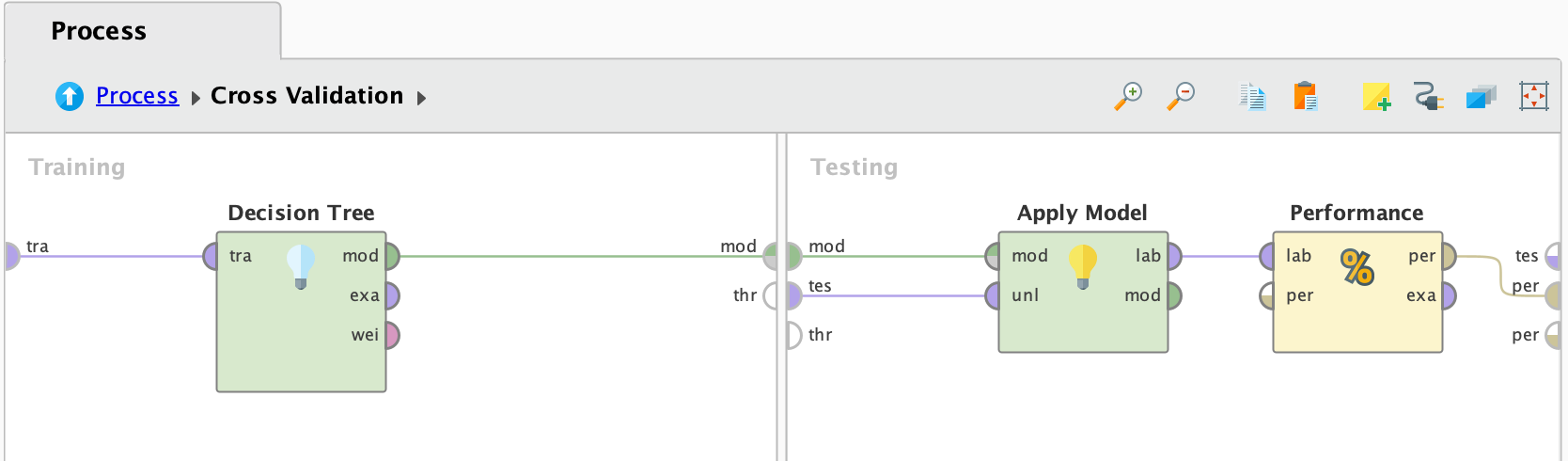
Los resultados de este modelo los veremos un par de secciones más adelante, cuando comparemos los resultados de los dos modelos creados.
Modelo con Python + scikit-learn
Definiendo el Procedimiento
El procedimiento que vamos a emplear es el clásico procedimiento en Python que engloba muchos casos de estudio: importamos librerías necesarias, descargamos el dataset y lo dividimos en el conjunto de entrenamiento y testing, creamos y entrenamos el modelo y, por último, evaluamos el modelo. Aunque como paso extra, esta vez nos interesa ver el árbol de decisión creado (algo particularmente interesante para estos modelos arborescentes), así que lo graficaremos como último paso.
Cada una de las siguientes celdas de código, ejecuta cada paso descrito, en orden.
Importando librerías necesarias
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score, classification_report
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Preparando el dataset
# Cargar el dataset Iris
data = load_iris()
X = data.data
y = data.target
# Dividir el conjunto de datos en datos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Creando y entrenando el modelo
# Crear un modelo de árbol de decisión
clf = DecisionTreeClassifier()
# Entrenar el modelo
clf.fit(X_train, y_train)Evaluando resultados
# Realizar predicciones en el conjunto de prueba
y_pred = clf.predict(X_test)
# Calcular la precisión del modelo
accuracy = accuracy_score(y_test, y_pred)
print("Precisión del modelo: {:.2f}%".format(accuracy * 100))
# Generar un reporte de clasificación
class_names = data.target_names
report = classification_report(y_test, y_pred, target_names=class_names)
print("Reporte de Clasificación:\n", report)Graficando el árbol de decisión obtenido
# Ver el árbol de decisión
plt.figure(figsize=(12, 8))
plot_tree(clf, filled=True, feature_names=data.feature_names, class_names=class_names)
plt.show()En particular, las salidas que nos interesa analizar son las últimas dos (los resultados del modelo y el árbol creado). Estas las analizamos en la siguiente sección.
Resultados
Aquí mostramos los resultados obtenidos para cada modelo en ambas plataformas.
Veamos primero el rendimiento del modelo creado en RapidMiner.
Resultado del modelo en RapidMiner

Como se ve claramente en la matriz de confusión, el resultado es bastante bueno. Aún así, notamos que el modelo clasificó incorrectamente 7 de los 150 ejemplos (4 Iris-versicolor y 3 Iris-virginica, en particular confundiéndolos entre sí).
El resultado del modelo entrenado en scikit-learn es el siguiente.
Resultado del modelo de scikit-learn
Precisión del modelo: 100.00%
Reporte de Clasificación:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 1.00 1.00 9
virginica 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30Como se puede ver, son perfectos. El hecho de que sean distintos a los obtenidos en RapidMiner se debe a los valores de los parámetros de los modelos, que difieren entre las plataformas. Esto, a su vez, resulta en árboles diferentes, como se verá a continuación.
En cuanto a los árboles obtenidos, son los siguientes.
Árbol de decisión en RapidMiner
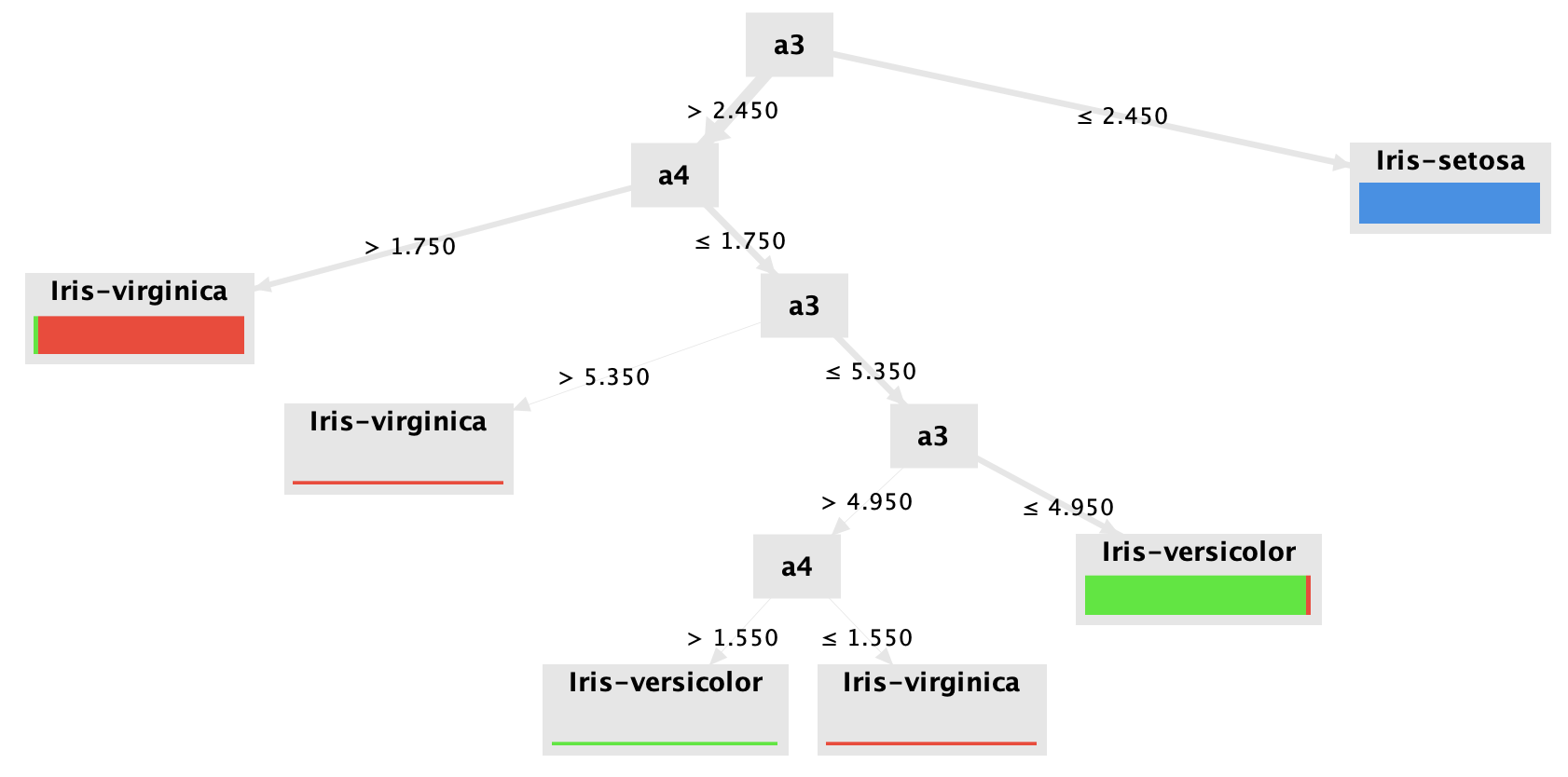
Árbol de decisión en scikit-learn

Estos árboles son bastante valiosos en casos donde necesitamos poder explicar qué decisiones tomó el modelo, o justificar su decisión. Muchas veces no es suficiente simplemente obtener una predicción; en algunos contextos poder explicar la decisión del algoritmo es fundamental, y por eso estos algoritmos de caja blanca son muy útiles.
Conclusión
Haciéndonos de dos plataformas como lo son RapidMiner y Python + scikit-learn, logramos encarar el mismo problema desde las dos, obteniendo dos modelos de árboles de decisión, además de analizar la performance de estos y su árbol resultado.