Nicolás Pavón
ANALYZING GOVERNMENT PURCHASES
It's all about money
In today's world, corruption is an issue that affects every
country. Therefore, having a standard to store government
purchases, like the
Open Contracting Data Standard (OCDS).,
plays a vital role in uncovering fraudulent activities and
financial misuse by the government. Luckily, in my home country,
Uruguay, this standard has been used since 2015 to store a wide
range of government purchases, and this data is publicly
available for free use on the
Datos Abiertos.
In this case study, we will analyze this data in search of
interesting patterns and characteristics, which hopefully (or
not), will reveal some misuse of government funds.
inspiration
While looking for a interesting dataset to demonstrate my ML skills, i came across the website Cuentas claras . In there, the owners try to reveal fraudulent purchases and misuse of government founds by applying a "function", which analyzes certain parameters and returns a value, in their case, "red flags". This idea of "red flags" is not new, and as we can see in the >OCDS website, this was already attempted by a few countries, and there are guides to work the OCDS data looking for these red flags.
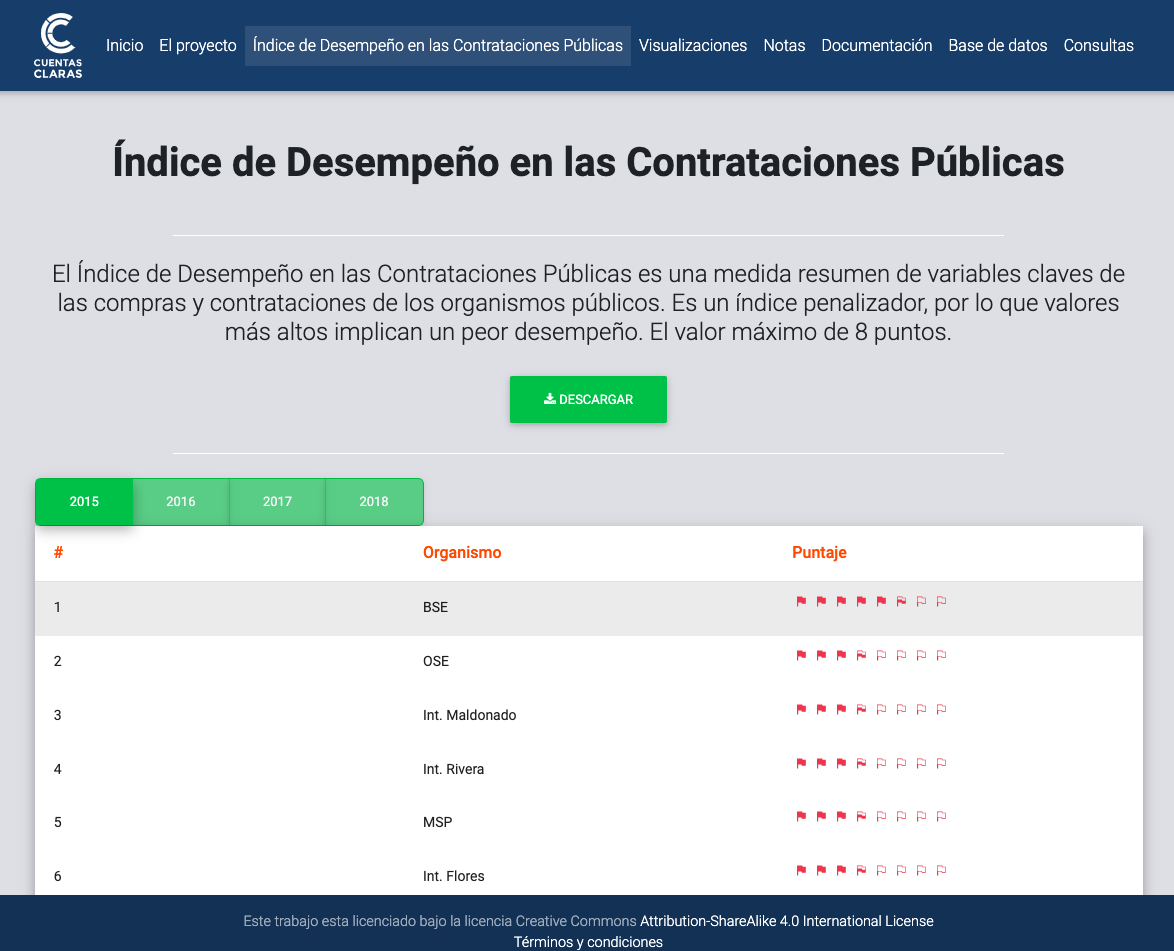
Cuentas claras website
I strongly reccomend taking a look into the website and explore
it. As you can see in the image above, they have succesfully
processed and classified purchases of many public government
organizations, marking them with the famous "red flags". Also
there are some interesting statistics to explore.
Sadly the "Cuentas claras" proyect does not provide the
processed data along with the "red flags", and after some failed
attempts in contacting the owners, it seems to be abandoned or
in standby state.
This is not good news. In order to train a predicting model wee
need already labelled data, luckily, the folks at "cuentas
claras" kind of described the process they took to flag
the organisms in
these documents. Taking this into account, there are
two possible paths to
continue working on this. We either "manually" label the data by
processing it with a similar function to the one used by cuentas
claras, or we try to apply clustering algorithms to identify
patterns and groupings, and then see if we can notice any odd
patterns that may indicate suspicious activity.
Or, we may try both approaches.
Manually labeling the data
Using
this guide
provided by the
Open
Contracting Partnership
organization it should be possible (in theory) to determine if a
certain purchase was 'suspicious,' as it provides a list with
possible 'red flags,' indicating the conditions that a purchase
must meet to raise suspicions.
After a brief investigation, we reached the conclusion that
determining that case by case is not a good idea for two
reasons:
- We are not qualified to analyze purchases and determine suspicious activities, since despite having that guide, we could never know with precision if it was truly a fraudulent purchase due to lack of context
- Labeling all that data is a very arduous and slow task.
Applying clustering
Although it wasn't the initial idea, by using clustering algorithms, we can study the information in different ways and eventually extract interesting conclusions. We might even be able to highlight certain purchases with interesting patterns... outliers.
Standard OCDS
The OCDS standard aims to store government procurement information in a clear, concise, and detailed manner. To achieve this, it provides a series of guides available on its website:
After further investigation of the standard, we concluded that a procurement process is broadly composed of:
-
A planning stage (Planning)
- Information about the planning phase of the procurement process. This includes information related to the process of deciding what to contract, when, and how.
-
A bidding stage (Tender)
- The activities carried out to award a contract.
-
An awarding stage (Awards)
- Information about the awarding phase of the procurement process. There may be more than one award per procurement process; for example, because the contract is divided among different suppliers, or because it is an ongoing offer.
-
A contracting stage(Contracts)
- Information about the contract creation phase in the procurement process.
As you can see, this is not a simple process. It consists of several stages that we won't delve into deeply for practical reasons, but in an ideal scenario, we can conclude that the standard seeks to be thorough and comprehensive when managing this information.
Red flags
After studying and understanding the standard, we further investigated the famous 'red flags', where we found a useful guide to understanding the data schema which explains in detail several possible cases of fraudulent activities
From this guide, we highlight some examples.:
- The available time to apply for the tender is very short (less than 2 days)
- The tender does not have a clear criterion for selecting the applicant nor key information such as dates, budget, etc.
- The tender is by invitation only.
These are the clearest examples we can observe, but there are a total of 64 possible red flags 🤯
Taking these red flags into account along with the data available in the standard, we make a pre-selection of the data that interests us. This list can be seen in detail in the team's repository
¿What about N-1 relations?
Considering that RapidMiner works (initially) with CSV files, where all the information about a purchase is in one row, it would not be possible to process purchases that contain N-1 relationships, where, for example, there are several bidders with different data for each one. So to study this problem, it's best to start with the simple path, selecting examples that can be processed using RapidMiner. To deal with this, we have developed a script that iterates over all purchases in an OCDS-formatted file, summarizing the relevant information from purchases that are good candidates for processing.
This was not a simple task, as we first had to define what information about a purchase is relevant based on the red flags definitions by OCDS, and then deal with the schema to successfully extract it, resolving different conflicts along the way such as the use of different currencies to indicate prices, among other issues. Feel free to contact me for more details about it.
Uruguayan data
Once we've assembled a script to condense the data into a CSV with relevant information, we process the available data from the Uruguay site and observe the worst... while data has been stored in quantity since 2002, this data is incomplete, containing only information on the quantity of items purchased and their unit price.
Buenos Aires data
Although this seemed like the end of the project, we remembered that this is an international standard and many countries follow it. After conducting a brief investigation, we found on their website a map with the countries adhering to the standard, where we observe Argentina. We enter the Argentine data website, download the dataset, and after processing it, we observe that it contains many more data points than the Uruguayan dataset.
But... is it enough?
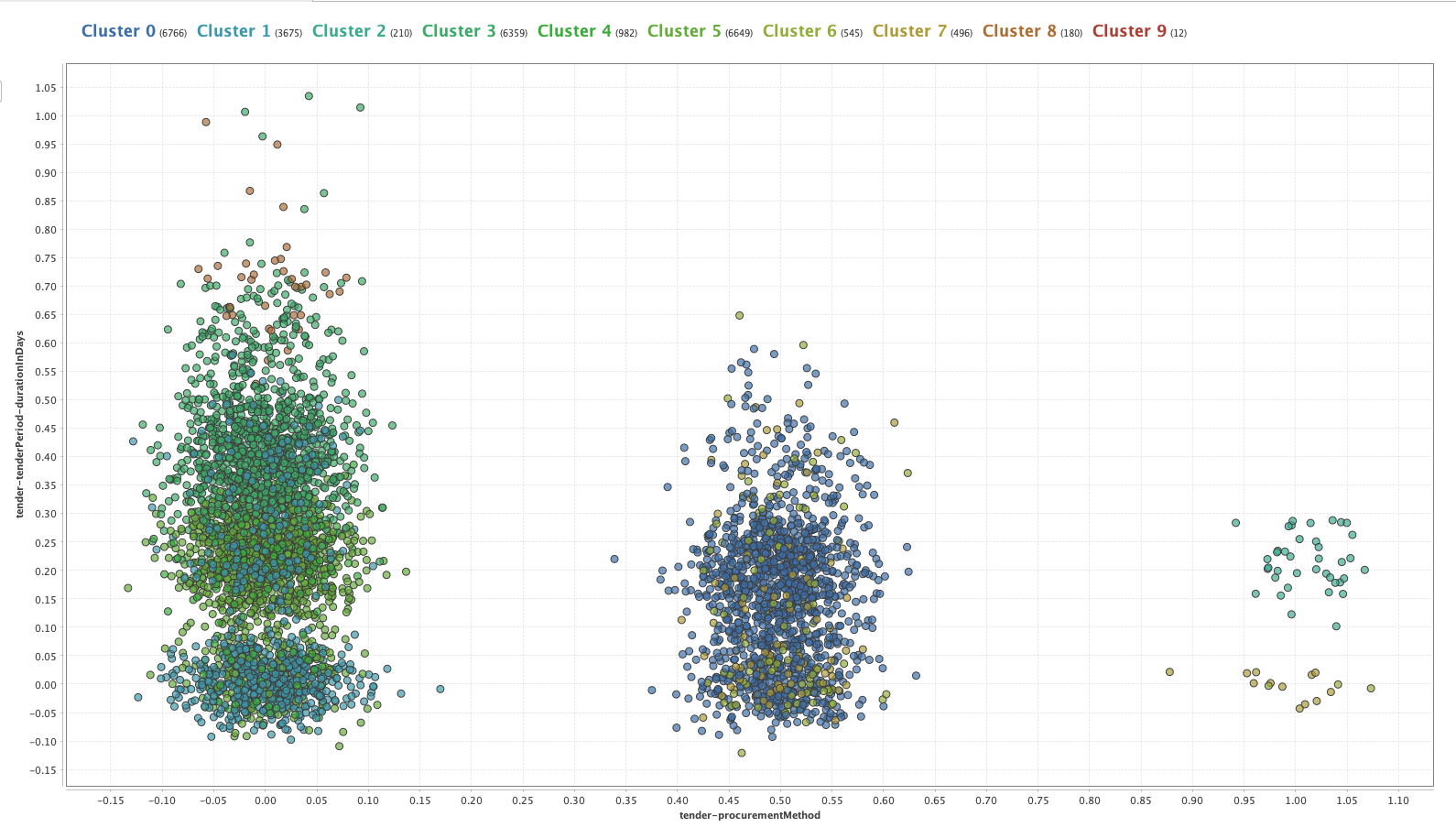
Duration of the bidding period vs. acquisition method
Conclusion
After applying clustering algorithms, we obtain somewhat discouraging results. We understand that patterns are detected, but nothing that strikes us as interesting at first glance. Although it is not the result we expected, we highlight that it is a great tool, and with more knowledge of the problem and quality data, it would be possible to find anomalies in the procurement processes of countries.Future of the project
One potential direction to further develop this project is by generating mock data. Thanks to the comprehensive work carried out by the OCDS standard, we have a clear understanding of the types of purchases that could raise red flags. Thus, we could generate multiple purchases with fabricated but detailed data that meet the criteria for red flags. Once this step is completed, we could theoretically train a machine learning model to identify these patterns, or alternatively, apply clustering algorithms to recognize how outliers would manifest within clusters formed using real dataHowever, it is important to have in mind that in order to correctly process government purchases with a ML model, first, we need the data to be complete with relevant information, which at least for the Uruguayan government, it's not the case.
Interesting Websites with Information on the Topic:
PowerPoint Presentation with Interesting Information on Red Flags and How to Use OCDS to Identify Them.Excel File with Definitions of Red Flags, ¡really useful! Videos from opencontracting.org Explaining How to Calculate Red Flags.
Frequently Asked Questions About Red Flags.
A Document Explaining in Depth the Use of OCDS and Red Flags.